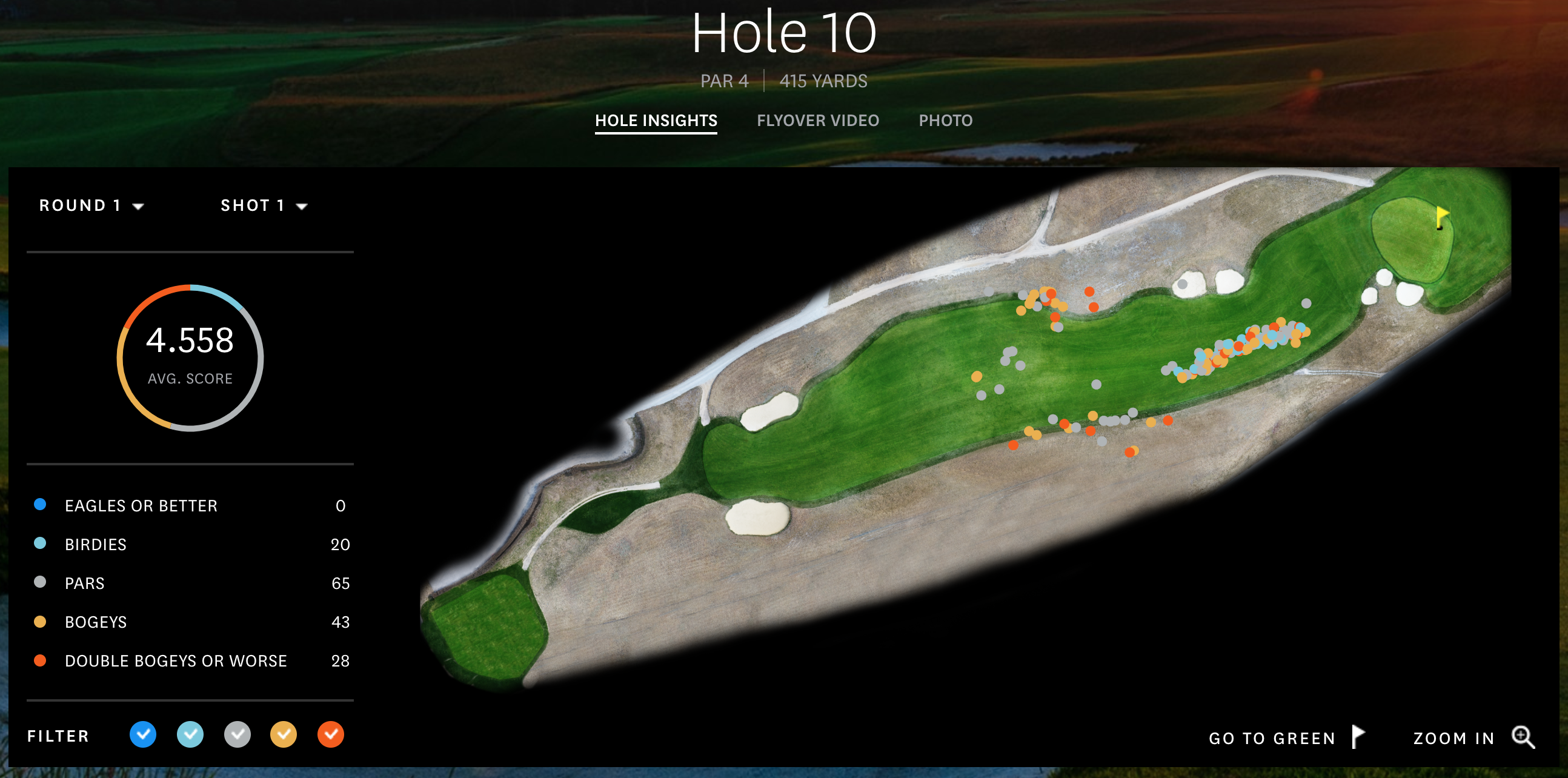
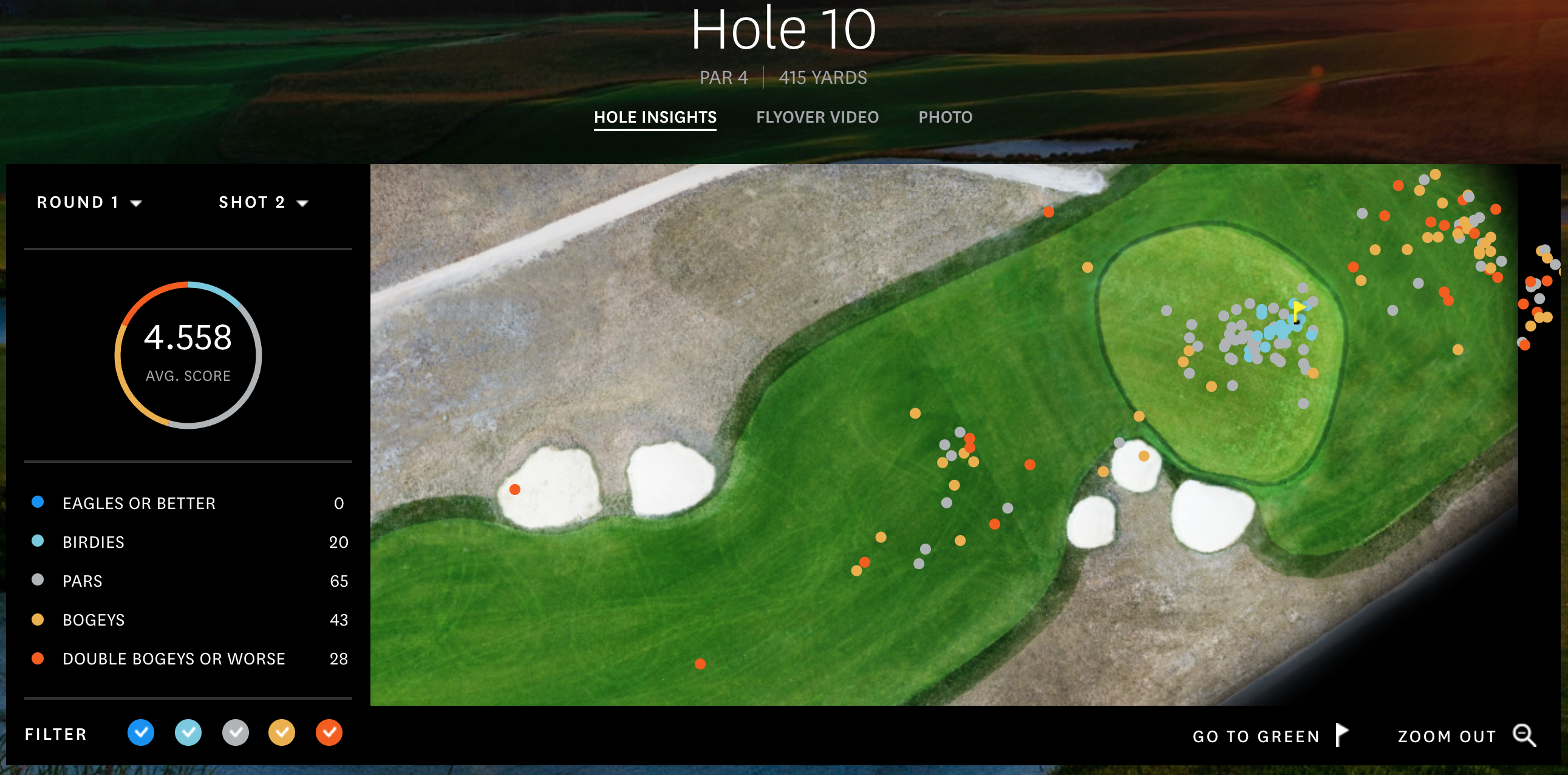
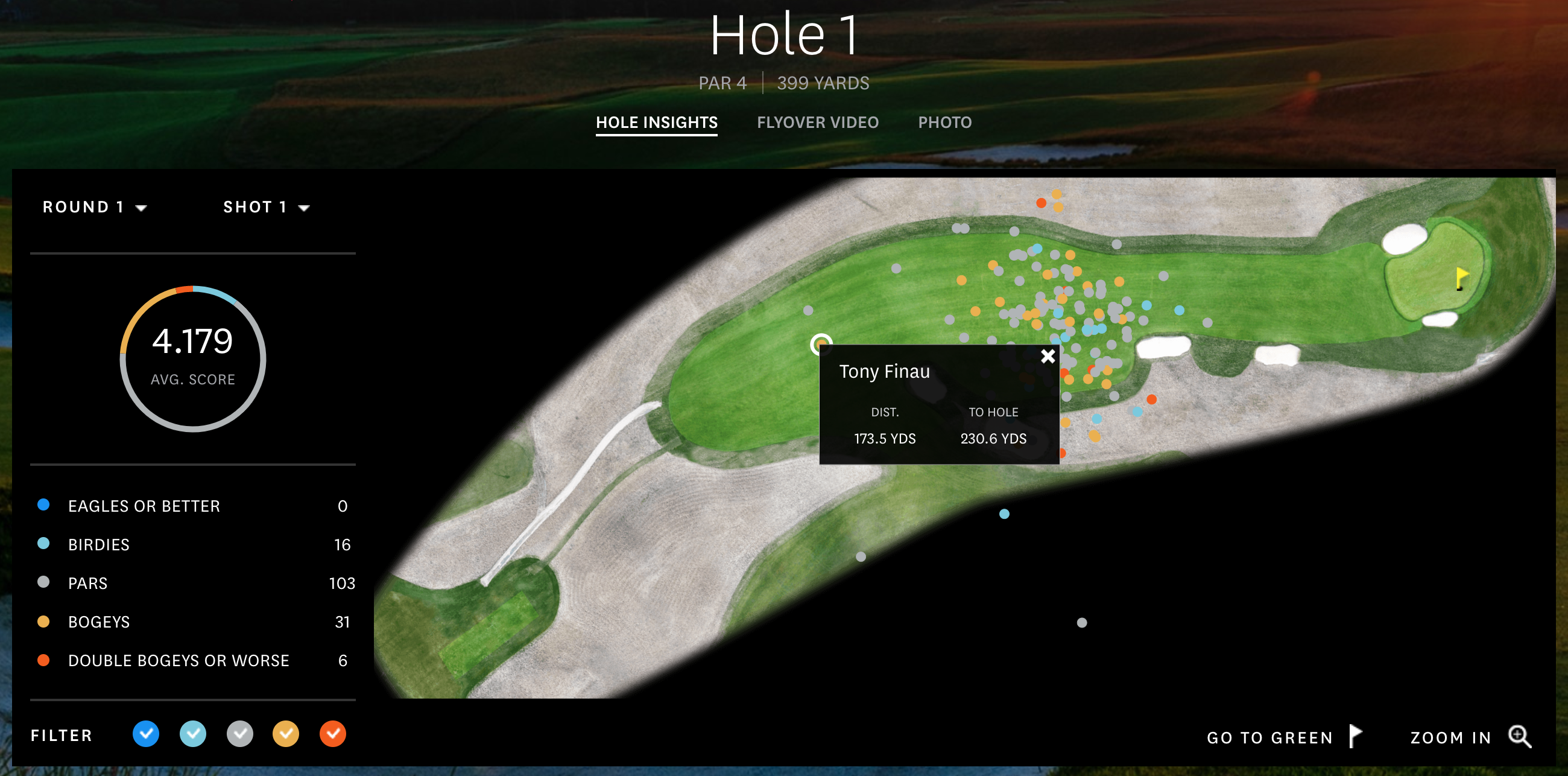
Pic when I was sitting courtside on Oct 24th, 2018. If you zoom in a little, you can see Giannis about to make a screen, while Embiid watches from the other side of the court to help out if the screen is successful. Both players were in the optimal lineup that night.
Opener
In the data world, when looking for projects or an interesting problem, sports almost always gives you the opportunity. For a lot of what I write, I talk about getting the data because the sports leagues rarely if ever give the data away. That gets a little repetitive, so I wanted to change it up to something interesting that’s done after you get the data, like how to optimize a lineup for NBA Daily Fantasy Sports (DFS).
Before continuing, I’ll say that this isn’t about me making money from betting. In the past season I made lineups for some of the nights, but realized quickly that in order to win, you really need to know a ton about the sport. I love watching the NBA in the winter, love watching the Bucks, but don’t follow all other teams close to enough compared to others. Still, I found it worth it to keep getting the data during the regular season and found it most interesting to find out who would have been in the best lineup that night, and then look back at the highlights to see why a certain player did well.
Because of that, I took the code I used, refactored it some, and wrote this up to show what I did to get to the point where I can calculate the best lineup.
Knapsacking
This optimization is generally categorized as a Knapsack problem. The wiki page for the Knapsack Problem defines it as follows:
“””Given a set of items, each with a weight and a value, determine the number of each item to include in a collection so that the total weight is less than or equal to a given limit and the total value is as large as possible.”””
Or, self described – If you’re stealing items of known value, but only are able to carry a certain amount of weight, how do you figure out which items to take?
This DFS problem though is slightly different than the standard Knapsack problem, and makes it much more interesting.
FanDuel Rules
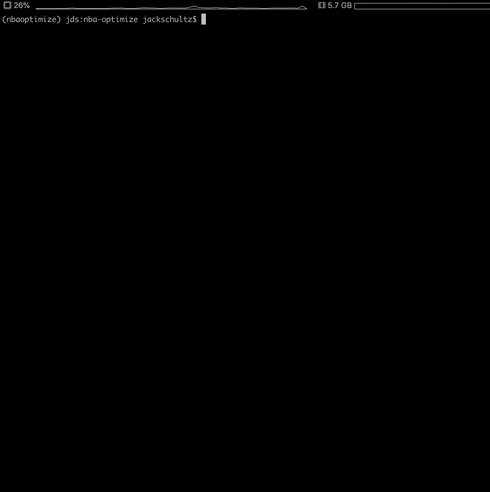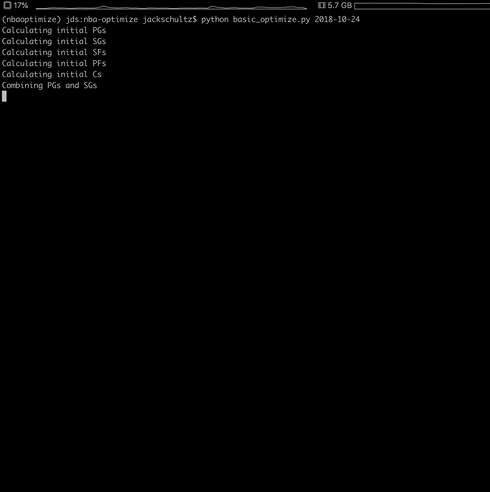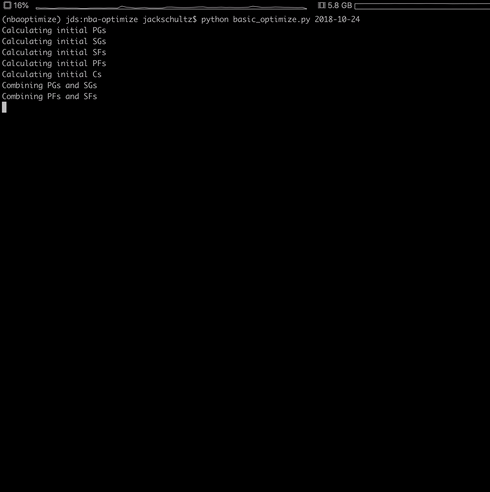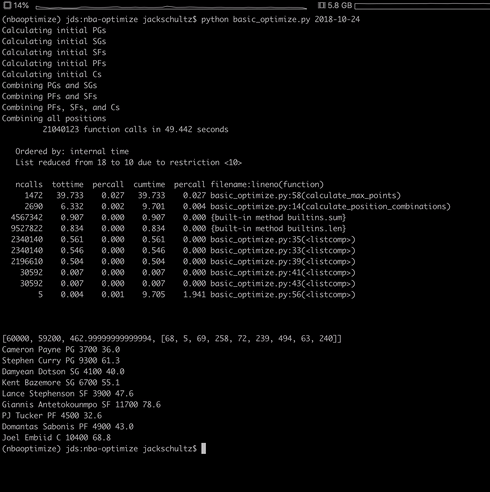
The DFS site I’m using for this is FanDuel, one of the two main Daily Fantasy Sports sites. Their rules for the NBA are that all players are assigned a position, Point Guard (PG), Shooting Guard (SG), Small Forward (SF), Power Forward (PF), and Center (C). A line up will have 2 PGs, 2 SGs, 2 SFs, 2 PFs, and 1 C. Each player is given a salary, and the combined salary of the players in your lineup must not be above $60,000. For reference, to give a sense of salary distribution, and what you’ll see in the final solution for best lineup of October 24th, 2018, MVP Giannis Antetokounmpo had a salary of $11,700, and ear blower and member of the Lakers Meme-Team, Lance Stephenson has a salary of $3,900. This data was given in csv files from FanDuel that we can download.
The amount of points a player gets depends on a bunch of stats for the night, positive points for things like actual points, rebounds, 3 point attempts made, assists, steals, and negative points for things like turnovers. This data comes from nba.com which I scraped and loaded into postgres.
Data
Below is a screenshot of what an example salary csv file that we can download looks like. Note that this is for a different date than the example day I’m using. I didn’t get the csv from FanDuel on that date, I had to scrape it from somewhere else, but it’s still important to give a look of what the csv file looks like. For our simple optimization, we only need the name, the position, and the salary of all the players.

Secondly, we need the stat lines which I then use to calculate the number of points a player got in a night. Below is a screenshot from stats.nba.com where it show’s how a player did that night. I have a script that scrapes that data the next day and puts that into the db.

If you look at the data csv files in the repo, all I have here is the name, position, salary, and points earned. This is a post about optimization, not about data gathering. If you’re wondering a little, here’s the query I used to get the data. I have players, positions, stat_lines, games, and some other tables. A lot of work goes into getting all this data synced up.
select p.id as pid, p.fd_name as name, sl.fd_positions as pos, sl.fd_salary as sal, sl.fd_points as pts from stat_lines sl join games g on sl.game_id=g.id join players p on p.id=sl.player_id where g.date='2018-10-24' and sl.fd_salary is not null order by sal desc
Code
Here’s the link to all the code on github. In it, you’ll find the csv files of data, three separate scripts to run the three different optimization methods, and three files for the Jupyter notebooks to look at a simplified example of the code.
Continuing
In the rest of the post, I’ll go through the three slightly different solutions for the problem. The first uses basic python elements and is pretty slow. The second brisk solution uses libraries like Pandas and NumPy to speed up the calculation quite a bit. The final fast solution goes beyond the second, ignoring most python structures, and uses matrices to improve the quickness an impressive amount.
In all cases, I made simple Jupyter files that go through how they each combine positions which hopefully give a little interactive example of the differences to try to show it more than words can do. In each case, when you go through them, you’ll see at the bottom they all return the same answer of what are the best players, what their combined salary is, and what their point totals are.
I talk about salaries, points, and indexes a lot. Salaries are the combined salaries of the players in a group, points are the combined points of the players in a group, and indexes are the the indexes from the csv file or the pandas dataframe which represent which players are in a group. Instead of indexes, we could use their names instead. Don’t get this confused when I talk about the indexes in the numpy arrays / matrixes that are needed to find which groupings are the best. To keep the index talk apart, I’ll refer to the indexes of the players as the player indexes. Also, I sometimes mix salary and cost, so if you see either of those words, they refer to the same thing.
If you have any questions, want clarification, or find mistakes, get in contact. Also I have twitter if you feel like looking at how little I tweet.
Basic solution
Time to talk about the solutions. There are effectively two parts to the problem at the start of basic. The first is combining the positions themselves together. From the FD rules, we need two PGs together. The goal of this is to return, for each salary as an input, the combination of players of the same position who have a combined salary less than the inputted salary with the most combined points.
Said a different way, for each salary of the test, we want to double loop through the same initial position array, and find the most successful combination where the combined salary is less than the salary we’re testing against.
The second part deals with combining each of those returned values together. Say we have the information about the best two PGs and the best two SGs. Again, for each salary as input, it returns the best combination of players below that salary. This is pretty much identical to what I said about the first part, with the only difference being that we didn’t start with two groups of the same players. Loop through the possible values of the salary possibilities, double loop through the arrays of positions, find the players who have the max points where the sum of their salaries is less than the salary value we’re testing.
There’s a lot of code in the solution, so I’ll post only a little, which was taken from the Jupyter file I created to further demonstrate. Click that, go through the lines of example code, and look at the double loops and see how the combinations are created. If you’re reading this, it’s worth it. To get a full look look here’s the link directly to the file on github.
#pgs, and sgs have the format of [(salary, points, [inds...])...] #where salary is the combined cost of the players with inds in inds, points is the sum of points. test_salary = 45000 #example test salary. max_found_points = 0 for g1 in pgs: for g2 in sgs: if g1[0] + g2[0] > test_salary: break #assuming in sorted salary order, which they are points = g1[1] + g2[1] if points > max_found_points: max_found_points = points top_players = g1[2] + g2[2] #combining two lists top_points = points top_sal = g1[0] + g2[0] return (top_sal, top_points, top_players) #after the loop we have a new tuple of the same format (salary, points, [inds]) #where this is the best combo of players in pgs and sgs who don't have a total salary #sum greater than the test salary
Here’s a slow gif of it running where you can see the time it takes to do the combinations. In the end, it prints out the names and info for the winners in the lineup. I also use cProfile and pstats to time the script, and also show where it’s being slow. This run took a tiny bit under 50 seconds to run (as you’ll see from the timing logs) so don’t think you’ll have to sit there and wait for minutes.
Brisk solution
After completing the first, most basic solution, it was time to move forward and write the solution which removes some of those loops by using numpy arrays.