After losing in a playoff to make it out of the local qualifying for the 2018 US Open at Shinnecock, I’m stuck at my apartment watching everyone struggle, wondering how much I’d be struggling if I was there myself.
Besides on TV, the US Open website offers some other way to follow what players are doing. As shown here, they very generously give us information on everyone’s shots on different holes. We’re able to see where people hit the ball, on which shot, and what their resulting score was on the hole. For example, why in the world did Tony Finau, the currently second ranked longest hitter on tour, hit it short off the first tee, leave himself 230 yards to the hole where he makes bogey?
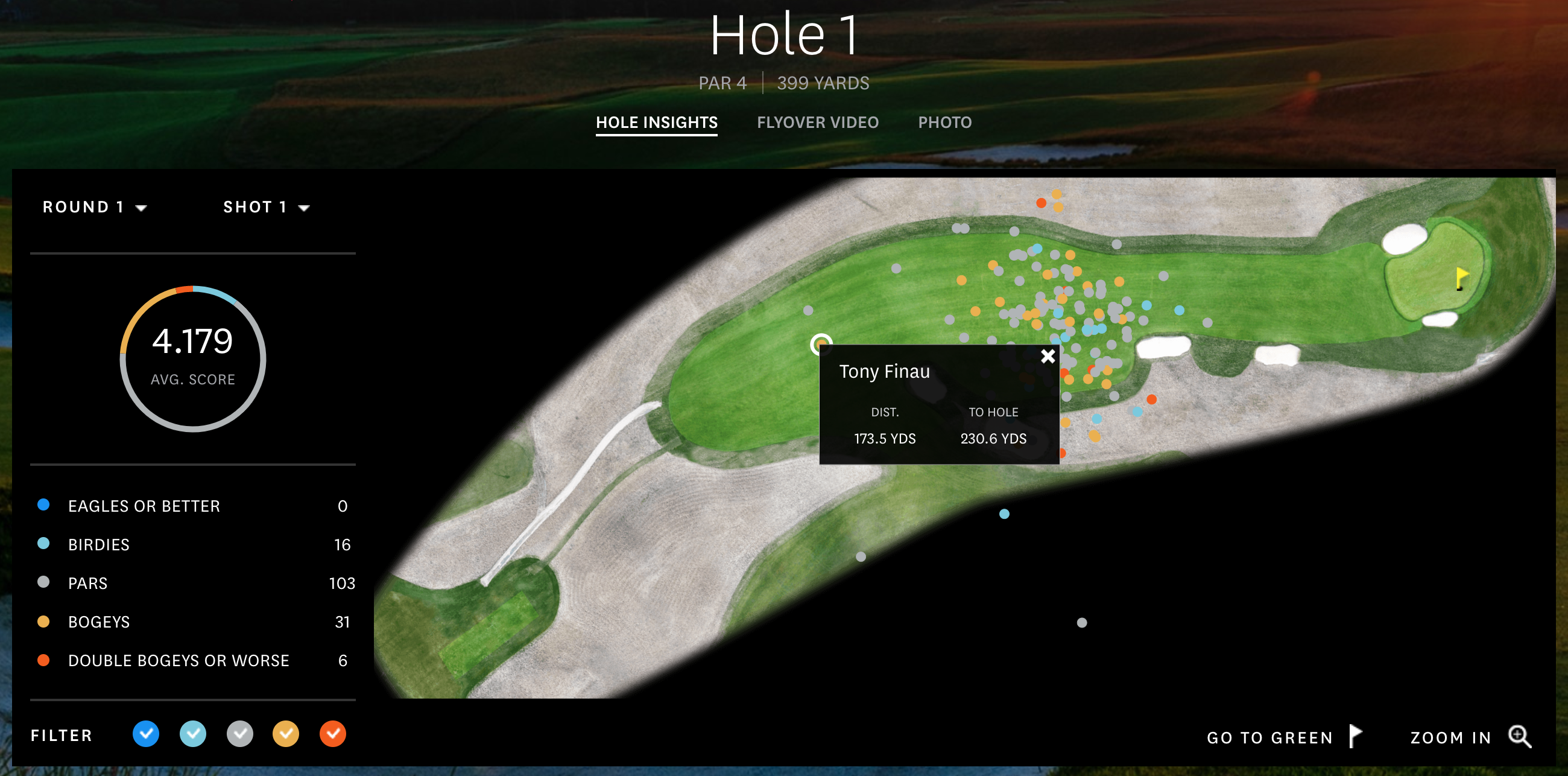
Why didn’t Tony rip D?
One of the cool things these images show is the groupings of all the shots on a hole, like the tee shots here. And when I see very specific and interactive data like we have here, I know it comes from somewhere that I’m able to see myself. So I figured I should grab that data and do some cluster analysis on different holes to see if there are certain spots that players like to hit it.
Here, I’ll go through the data we have, what the values and the numbers mean, and also the code I wrote to eat up the data and display the graphs. Once I have this part going, I’ll be able to perform further analysis to most things that come to mind.
Any questions, comments, concerns, trash talking, get in touch: twitter, contact.
Current Posts
Using Clustering Algorithms to Analyze Golf Shots
Finding the data
First step was to search for where the data for the hole insights page was coming from. As always, open the dev tools, click on the network tab, and find what’s getting called with a pretty name.
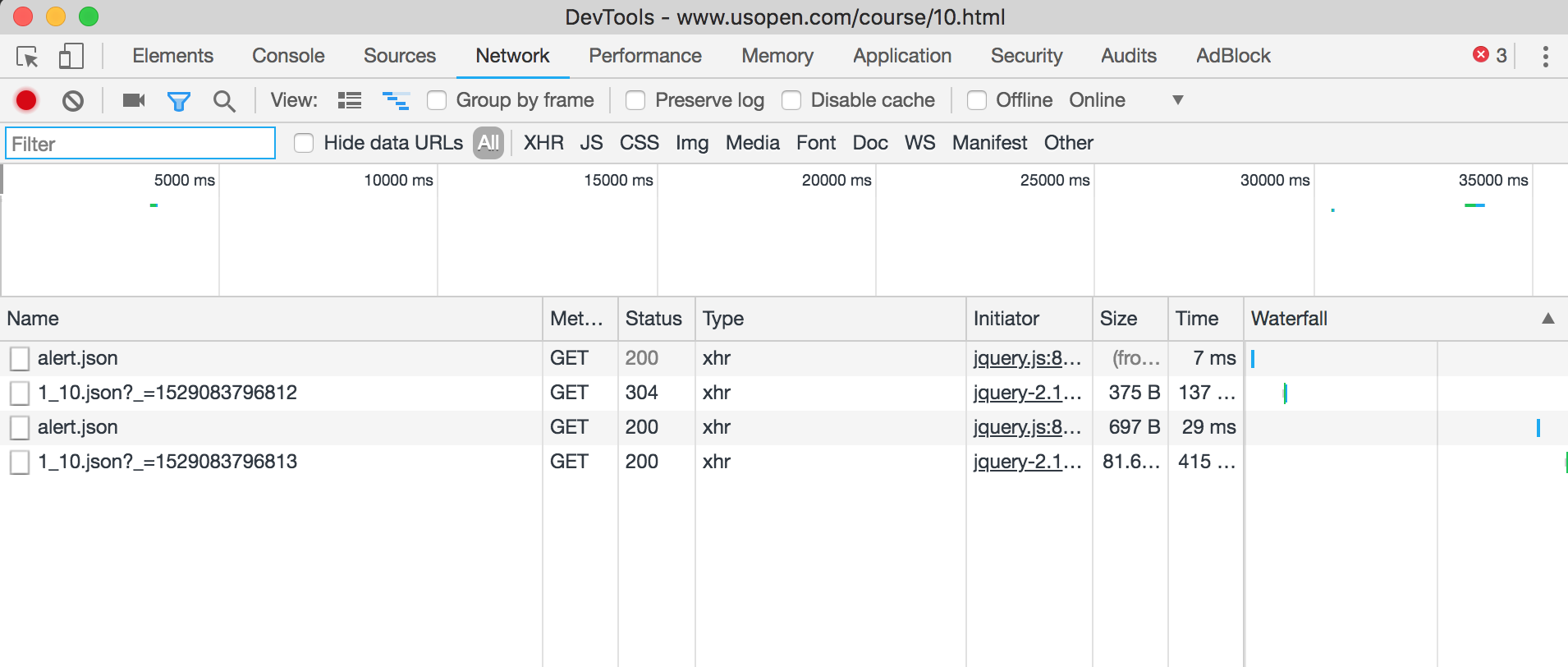
Alert!
The file itself is quite dense and has all the information, which is really cool! It has IDs for all the players, all the shots they have on the hole, which include the starting distance from the flag and the ending distance to the flag.
First off, we’re given a list of Ps, meaning an array of player information, like this:
...
{u'FN': u'Justin', u'ID': u'33448', u'IsA': False, u'LN': u'Thomas', u'Nat': u'USA', u'SN': u'THOMAS'},
{u'FN': u'Dustin', u'ID': u'30925', u'IsA': False, u'LN': u'Johnson', u'Nat': u'USA',u'SN': u'JOHNSON D'}
{u'FN': u'Tiger', u'ID': u'08793', u'IsA': False, u'LN': u'Woods', u'Nat': u'USA', u'SN': u'WOODS'}
...
It looks like we have first name, player’s ID, whether or not they’re an amateur, last name, nationality, scoreboard name. The important part of this information is the ID, where we’ll be able to match players to shots.
Next, we’re given a few stats on the hole for the day:
