After losing in a playoff to make it out of the local qualifying for the 2018 US Open at Shinnecock, I’m stuck at my apartment watching everyone struggle, wondering how much I’d be struggling if I was there myself.
Besides on TV, the US Open website offers some other way to follow what players are doing. As shown here, they very generously give us information on everyone’s shots on different holes. We’re able to see where people hit the ball, on which shot, and what their resulting score was on the hole. For example, why in the world did Tony Finau, the currently second ranked longest hitter on tour, hit it short off the first tee, leave himself 230 yards to the hole where he makes bogey?
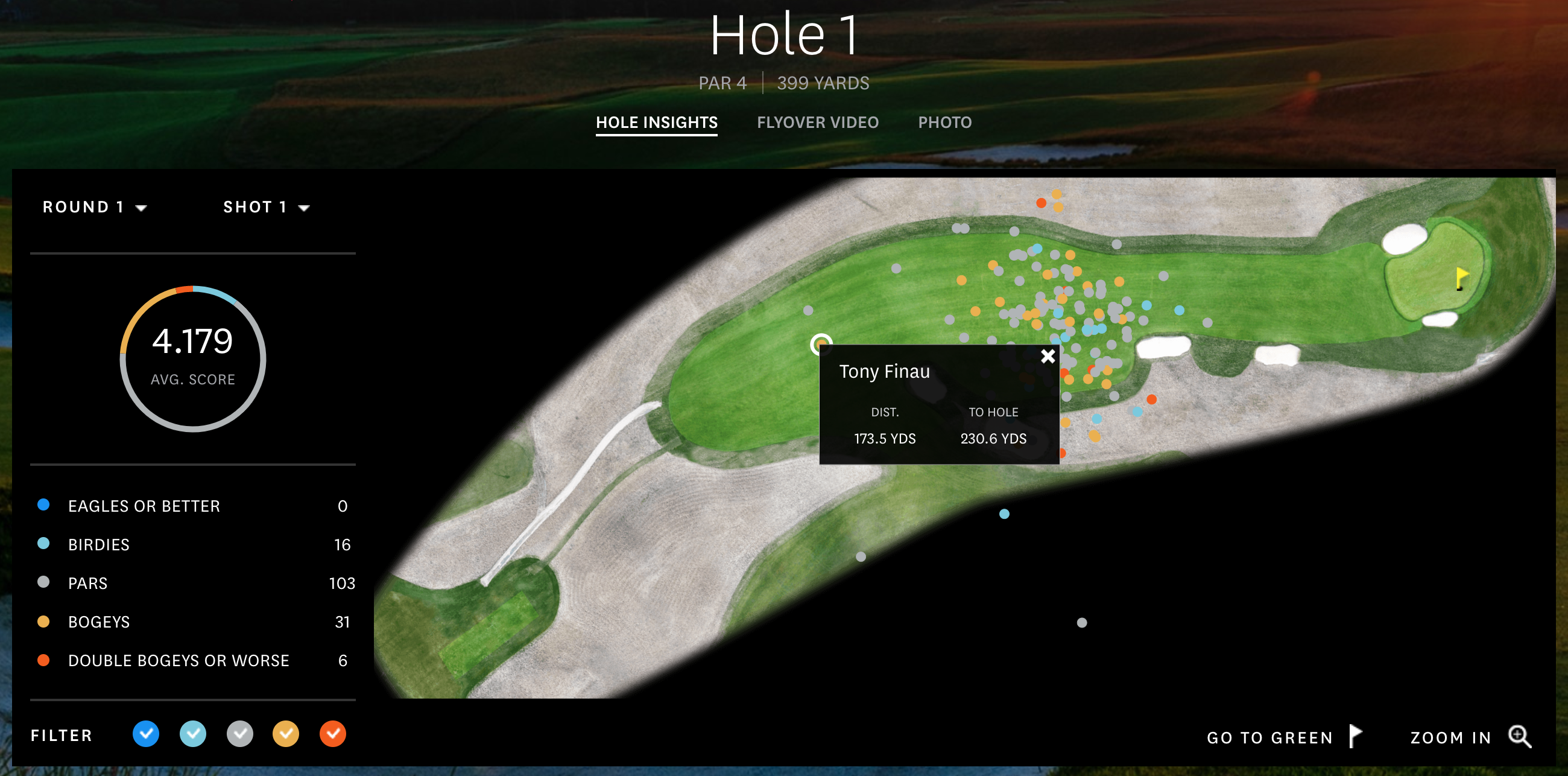
Why didn’t Tony rip D?
One of the cool things these images show is the groupings of all the shots on a hole, like the tee shots here. And when I see very specific and interactive data like we have here, I know it comes from somewhere that I’m able to see myself. So I figured I should grab that data and do some cluster analysis on different holes to see if there are certain spots that players like to hit it.
Here, I’ll go through the data we have, what the values and the numbers mean, and also the code I wrote to eat up the data and display the graphs. Once I have this part going, I’ll be able to perform further analysis to most things that come to mind.
Any questions, comments, concerns, trash talking, get in touch: twitter, contact.
Current Posts
Using Clustering Algorithms to Analyze Golf Shots
Finding the data
First step was to search for where the data for the hole insights page was coming from. As always, open the dev tools, click on the network tab, and find what’s getting called with a pretty name.
Alert!
The file itself is quite dense and has all the information, which is really cool! It has IDs for all the players, all the shots they have on the hole, which include the starting distance from the flag and the ending distance to the flag.
First off, we’re given a list of Ps, meaning an array of player information, like this:
...
{u'FN': u'Justin', u'ID': u'33448', u'IsA': False, u'LN': u'Thomas', u'Nat': u'USA', u'SN': u'THOMAS'},
{u'FN': u'Dustin', u'ID': u'30925', u'IsA': False, u'LN': u'Johnson', u'Nat': u'USA',u'SN': u'JOHNSON D'}
{u'FN': u'Tiger', u'ID': u'08793', u'IsA': False, u'LN': u'Woods', u'Nat': u'USA', u'SN': u'WOODS'}
...
It looks like we have first name, player’s ID, whether or not they’re an amateur, last name, nationality, scoreboard name. The important part of this information is the ID, where we’ll be able to match players to shots.
Next, we’re given a few stats on the hole for the day:
[{u'Avg': u'4.558',
u'Bir': 20,
u'Bog': 43,
u'DBg': 28,
u'Eag': 0,
u'Fg': {u'X': 1417011.593, u'Y': 268520.819},
u'HPs': [....],
u'HY': 418,
u'ID': 10,
u'Par': 4,
u'Prs': 65,
u'Rnk': u'4',
u'Te': {u'X': 1415802.808, u'Y': 268819.161}}]
Which match up nicely with what we’re shown on the image
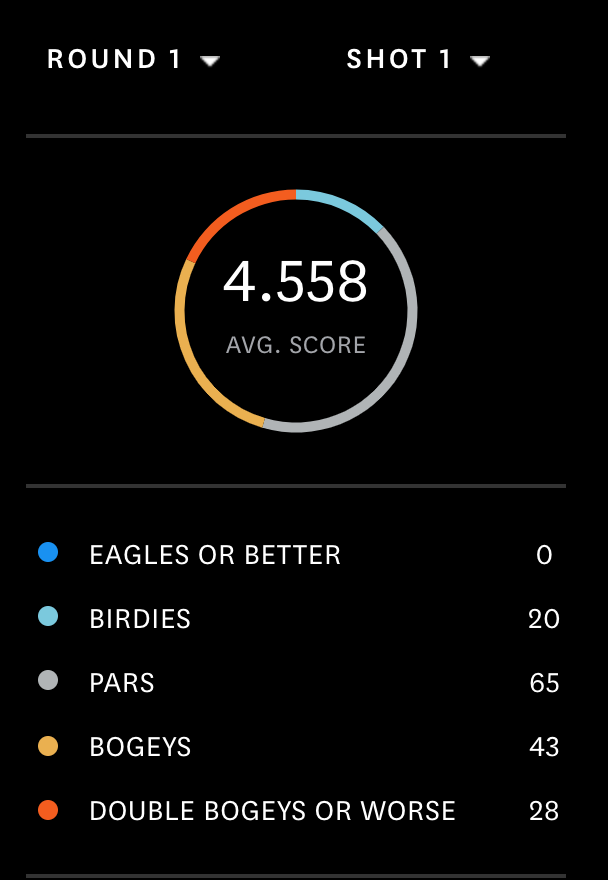
Birdies, Pars, and Bogeys, oh my
Shots
See that HP tag above? That’s where the information on the shots players have hit are stored. Each shot in the JSON is listed like the following, which is Tiger’s tee shot on number 10.
{u'DTP': 5937.3, u'Dis': 9047.1, u'IsIn': False, u'No': 1, u'X': 1416521.955, u'Y': 268593.013, u'ZID': 20}
Going through acronyms again, we have distance to pin, distance of shot itself, is the shot in the hole, X coordinate, Y coordinate, ZID which I don’t know what that means.
The first step for me was to go through and make sure I understand what those coordinates mean. To do this, I took a little time to try to match up the X and Y coordinates of the shot ending points, and where they tell us the flag is located.
In order to calculate the distance of the tee shot, or rather, the location of the flag, we’re going to do some math using the Pythagorean Theorem!
import math dtp = 5937.3 #distance to pin after shot fgx = 1417011.593 # flag's x position fgy = 268520.819 # flag's y position tsx = 1416521.955 # tee shot's x position tsy = 268593.013 # tee shot's y position dist = math.hypot(fgy - tsy, fgx - tsx) print dist / 3.0 print dtp / 36.0 >>> import math >>> dtp = 5937.3 #distance to pin after shot >>> >>> fgx = 1417011.593 # flag's x position >>> fgy = 268520.819 # flag's y position >>> tsx = 1416521.955 # tee shot's x position >>> tsy = 268593.013 # tee shot's y position >>> dist = math.hypot(fgy - tsy, fgx - tsx) >>> print dist / 3.0 # apparently dist is in feet 164.977218858 >>> print dtp / 36.0 # and then the dtp is in inches. Why? I dunno 164.925
Neato, the math checks out. In terms of clustering though, it doesn’t make much of a difference other than knowing that we have correct data.
Cleaning and formatting
I keep saying that the main part of data work is gathering and formatting and cleaning the data before throwing the variables into a function that’s already been written. And that’s the case here too. The goal is to have an array of [x, y] coordinates for the result of the tee shot.
with open('1_10.json') as f:
data = json.load(f)
fg = data['Rs'][0]['Hs'][0]['Fg']
print fg # {u'Y': 268520.819, u'X': 1417011.593}
fgx = fg['X']
fgy = fg['Y']
locs = []
hps = data['Rs'][0]['Hs'][0]['HPs']
for hp in hps:
sk = hp['Sks'][1]
print sk # {u'No': 2, u'ZID': 1, u'X': 1417095.696, u'Y': 268519.862, u'IsIn': False, u'DTP': 1008.3, u'Dis': 3592.9}
skx = sk['X']
sky = sk['Y']
diff_x = fgx - skx
diff_x = skx - fgx
diff_y = fgy - sky
locs.append([diff_y, diff_x])
print np.array(locs)
'''
[[ -3.167 -214.564]
[ -25.146 -247.396]
[ -37.92 -252.717]
[ -33.195 -281.108]
[ -71.133 -464.982]
....
[ -49.785 -318.032]
[-218.516 -416.785]
[ -2.429 -210.111]
[ -18.842 -234.01 ]
[ -43.724 -351.278]
[ -61.787 -361.844]]
'''
Clean looking code, and gets us the differences we’re looking for.
Scikit-Learn Cluster Algorithms
I’ll go a little further than only understanding the data, and also show the code that I use to find the clusters of the data.
To do this, we take that locs array and throw it into the sklearn algorithms.
from sklearn import cluster num_clusters = 4 ## DB Scan core_samples, dbs_labels = cluster.dbscan(locs, eps=50) ##K Means centroid, km_labels, inertia = cluster.k_means(locs, n_clusters=num_clusters) ## Aglomerative Clustering ac = cluster.AgglomerativeClustering(n_clusters=num_clusters).fit(locs) ac_labels = ac.labels_ ## Affinity Propagation ap = cluster.AffinityPropagation(preference=-45000).fit(locs) ap_labels = ap.labels_ ## Birch birch = cluster.Birch(n_clusters=num_clusters).fit(locs) birch_labels = birch.labels_ ## Spectral Clustering spectral = cluster.SpectralClustering(n_clusters=num_clusters, eigen_solver='arpack', affinity="nearest_neighbors").fit(locs) s_labels = spectral.labels_
Now that’s super easy. The resulting x_label variables are arrays of the same length as the locs variable, meaning 156 since there are 156 players. The number at each location in the array is what group the shot belongs to. So for example, if we’re using the K Means algorithm with 3 groupings, the array has values of 0, 1, and 2, like the following:
>>> print km_labels [1 1 1 1 0 1 1 1 1 1 1 1 1 1 2 2 0 1 1 1 1 2 0 1 2 1 1 1 1 2 0 1 1 1 1 1 2 1 1 1 1 2 1 1 0 2 2 1 0 2 0 1 1 1 1 1 1 0 1 2 1 1 1 1 2 1 0 0 1 2 0 1 1 0 1 1 0 1 1 1 1 2 2 1 1 1 1 2 1 0 1 1 1 1 1 1 1 0 1 1 2 1 2 1 1 1 1 1 1 1 1 1 1 1 0 2 2 1 1 1 1 0 1 1 2 2 1 0 2 1 0 1 0 2 2 2 1 1 2 1 1 1 1 1 1 1 1 2 2 1 1 2 1 1 1 1]
Graph time
The code that I’ll use to show the resulting clusters is the following.
num_found_clusters = set(plotting_labels) #plotting labels is any one of the x_labels variables above
colors = cycle('bgrcmykbgrcmyk')
for k, color in zip(num_found_clusters, colors):
class_members = plotting_labels == k
group_locs = [x for x, y in zip(locs, class_members) if y]
xs = [val[0] for val in group_locs]
ys = [val[1] for val in group_locs]
plt.plot(xs, ys, color + 'o') #dotted points, which is where the 'o' comes in
plt.show()
I’m going to hide the cluster results until part two which will have the pretty pictures, but now I’ll show a graph that just lists the points.
To do this, all I’m going to do is set num_clusters = 1 and plotting_labels = km_labels, then it’ll spit out a graph with no heading, no x or y labels, and a bunch of blue dotted dots.
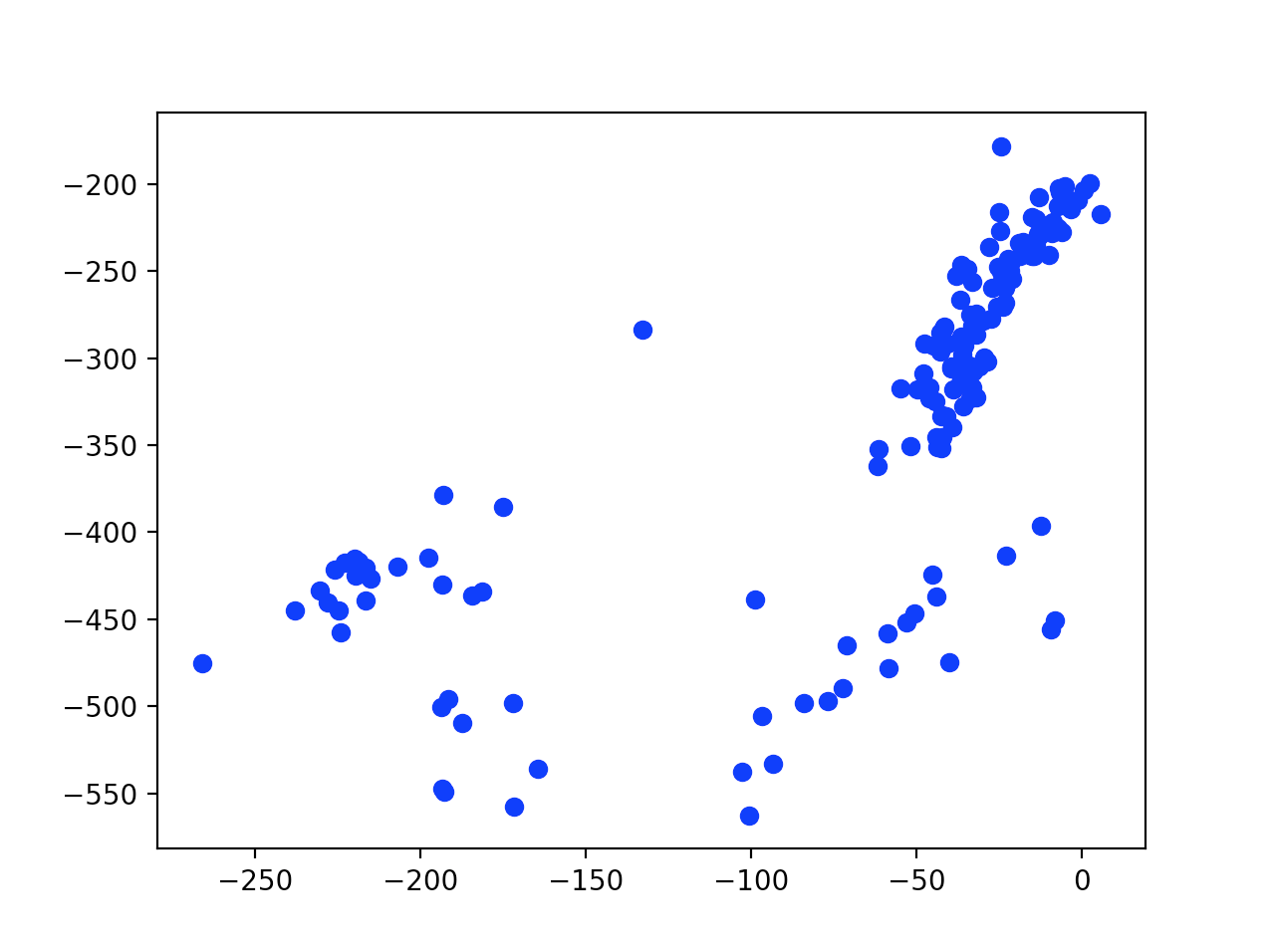
Blue dotted dots
Do you see some clusters?? I do, and now we want to see how those algorithms above find them. Look for more posts to come using this data.
