Hello!
If I’d wanted to really grab your attention, I should have title this article something like 13 Tips that Could Save You Years of Effort or A Guide to Becoming a Full Stack Developer in 2017. But I don’t know how to save you years of effort and I can’t write a comprehensive guide and, frankly, I am not interested in pretending like I do! So instead, you get a boring but honest title, and my thoughts as someone who is not an expert and who is not planning to make a career out of programming.
I’m Sara, Jack’s older sister, and I have the privilege of writing a guest post today! My background is not in anything related to programming – I am a CPA and spent over five years working as a public accountant, mostly in corporate tax.
So how does my background give me any right to be posting on this blog? I am now an MBA student and as part of my curriculum, I took a Business Statistics class which involved learning how to use R. I am not sure I can even say I had heard of R before taking this class, so there was steep learning curve for me.
I spent a lot of time thinking about what I could actually write in this post that might be useful to Jack’s readers, since you could all out-program me in your sleep. My first draft of this post involved a lot of specifics regarding the questions I was assigned and how I solved them, but that didn’t seem helpful to anyone. Plus, although I did well on my assignment, I’m not totally sure what I did right versus what I did wrong.
Instead, I’ve decided to share a few of the insights I gleaned from my brief experience as a programmer, and also some of the resources I used to teach myself as I completed my assignments. I’d like to note that just like I’m new to programming, I’m new to writing about programming, so I assume this post will be unlike most others on the subject.
If you’re like me and you are new to programming, hopefully this will help you get started. If I learned one thing, you can’t just be taught how to do this, but maybe this will give you some inspiration.
Play around, but make sure you have an idea / project in mind
Considering I’m such a rookie, the first thing I needed to learn how to do wasn’t writing code, but installing R.
https://www.youtube.com/watch?v=A56PD8BSS0A
We then spent an entire class session following along as our professor demonstrated the very basics of R. This proved to be invaluable – I wouldn’t have even felt comfortable knowing where to even begin otherwise.
I think it’s important to note that although we were just playing with various functions, we were doing that in relation to one of the problems we’d been assigned. With his guidance, we were able to see how we should begin to work the problem, and how various functions could help meet our goal. It seemed to me that learning various functions through experimentation is useful, but you’ve got to make sure you’re working towards a goal as you do so.
The example we went over in class involved determining whether a specific pitcher for the Oakland As influenced the team’s ticket sales.
Following along with my professor, we named our data “As”, and then my very first lines into R looked like this:
> names(As) [1] "TICKET" "OPP" "POS" "GB" "DOW" "TEMP" "PREC" "TOG" [9] "TV" "PROMO" "NOBEL" "WKEND" "OD" "DH" > As(1,) Error in As(1, ) : could not find function "As" > As[1,] TICKET OPP POS GB DOW TEMP PREC TOG TV PROMO NOBEL WKEND OD DH 1 24415 2 5 1 4 57 0 2 0 0 0 0 1 0
As you can see, I made my first mistake right off the bat, using parentheses instead of brackets. After that first time, I don’t think I made that mistake again. Only through making the mistake and getting the error message did I figure out what I’d done wrong.
This proved to be the case time and time again as I made my way through the assignment, and I quickly learned mistakes are a way of life in programming. Somewhat infuriatingly, R returned just a blanket “error” message without much direction as to where I went wrong. I do think this helped me with my critical thinking, as it was up to me to figure out exactly where I had errored.
Bottom line: the time I spent tinkering around in R was when I learned the most. Figuring out how to correct errors was more instructive than getting it right the first time.
Time estimates are useless
In my career as a CPA, I could more or less predict how long various tasks would take. In fact, I usually had the previous year’s time reports to consult to see how much time we’d taken to complete the task in the past. I quickly found this is not the case with programming.
I sat down to work on my assignment on a beautiful summer Saturday, expecting it to take me a few hours maximum. By the time all was said and done, it took me probably ten hours to complete the three questions, spread over a few days. I talked to my classmates after we’d finished the assignment, and there was a wide array of time spend. People reported getting hung up on various parts, and there’s no telling how long it might take to work through the rough patches.
Maybe with more experience you get better at estimating how long projects take, but I have a strong hunch that you’ll often find you don’t know what you’re in for until you’re in the thick of it. I’m sure glad I started working on my assignment a week before it was due.
Don’t be embarrassed to google everything
If you’re having trouble with a specific function, chances are someone else out there has as well, and has asked the internet about it. Sometimes I didn’t even know what exactly it was that I was googling, but that generally didn’t matter as long as I hit the right keywords.
I often found myself reading helpful hints on various websites, and would cross-reference the notes I had from class. It quickly became clear to me that there’s no right way to do something. The way my professor showed an example in class was not how the people posting on Stackify perform the same task, and that’s ok. I actually think I learned more by seeing alternative ways of performing the same function.
I may be totally off base in saying this, but from all the googling I did, it seems to me that the exact lines of code one person uses to complete a project is as distinctive as their handwriting. I was not expecting programming to be such an individualized process.
I’m also not embarrassed to say that that’s how I solved a lot of my errors. This actually reminded me a lot of my accounting career. For many research projects, I often began by consulting google, and our firm definitely encouraged that.
Sleep on it
As I neared the end of my assignment, I got began to get very frustrated when something that I thought I’d mastered was not working out. I couldn’t figure out what I was doing wrong. I had more or less finished the question, and only had to insert a line of best fit into my scatter plot.
No matter what I did, that dang line would not appear.
As much as I wanted to finish the assignment that day, Jack wisely advised me that it would do no good to keep typing the same code, hoping that the line would magically generate. After a few minutes of doing exactly that, I concluded that he was correct. So… I went to sleep.
The next morning, I woke up and found my last few lines of code:
> plot(TICEKT,fit0$residual+fit0$fitted.values,pch=20)
Error in plot(TICEKT, fit0$residual + fit0$fitted.values, pch = 20)
Can you spot my error? Yep, “TICEKT” is not a word. (Is now a good time to note that I was also an English major?)
I corrected my error and produced this beautiful result:
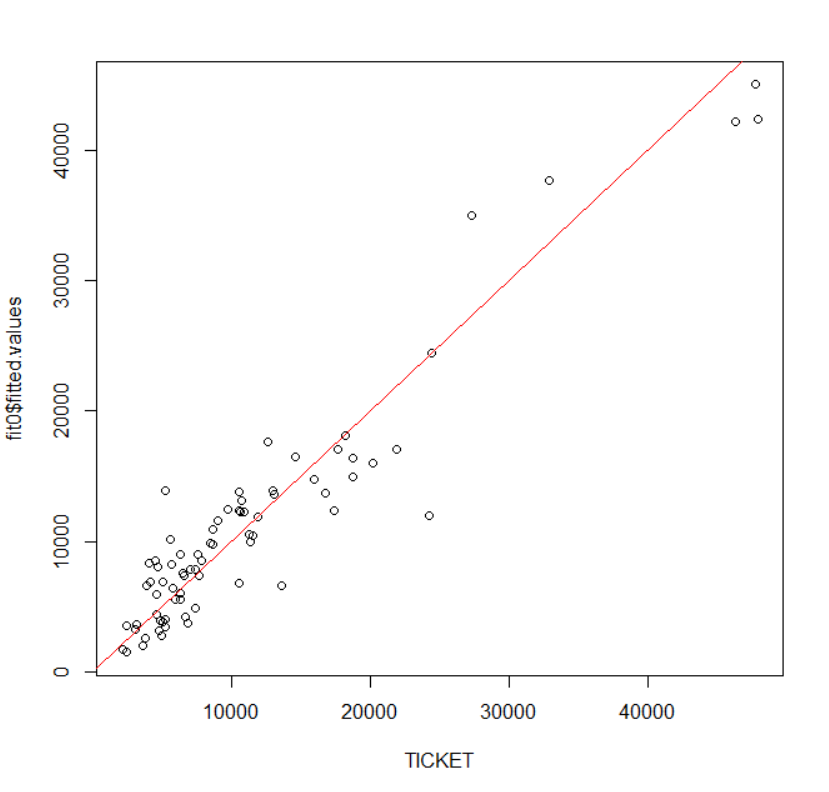
I’m sure not all errors are that easily solvable with a good night of sleep, but I got lucky. I think this applies to lots of areas of life; if you leave things to ruminate a bit, you might just find a better answer. Or in my case, a line!
Always more to learn
I spoke to Jack about this assignment a little, and explained what it was I was asked to do. Until our conversation, it did not occur to me that there had been a lot of work on the front-end to get the data for our project ready to go.
For example, here’s a screenshot of a small portion of the data our professor provided:

(etc. etc. etc. etc.)
How did this data get here? When I was completing the assignment, I honestly didn’t care, and didn’t even think to care. I just felt incredibly smart for “mastering” R and successfully completing the assignment and making the beautiful plot I posted above. I was thinking to myself that I probably should have skipped this class and put myself directly into the more advanced Regressions class.
I came to my senses. Upon further reflection, it sure seems like compiling all this information is a heck of a lot harder than actually analyzing it! Jack then explained to me that all those articles I proofread for him about scraping data are doing exactly that. And those articles go so far over my head that hearing that brought be back to Earth about my only adequate capabilities.
There’s actually a term for this (credit to Jack for introducing me to it.) It’s called the Dunning-Kruger effect, which Wikipedia summarizes as when “persons of low ability suffer from illusory superiority when they mistakenly assess their cognitive ability as greater than it is.”
Well here I am, a person of “low ability” who has seen the light. I know that I don’t know what I don’t know. I used to know nothing about programming, but I have now progressed to knowing next to nothing about programming. At the very least, Jack’s articles now make more sense to me!