This is the second sub problem that I’ve encountered in my DFS golf optimization / forecasting endeavor. The full post on what I’m working on is coming, and I’ll post the link to that here after I finished writing it. This sub problem here deals with finding a value function for how much a golfer is worth depending on where they’re projected to finish in the tournament.
In DFS, each golfer (or player for other sports) is given a salary that shows how much they’re worth. Your job is to come up with a combination of players that give the highest point total so that the sum of their salaries isn’t more than the salary cap. In general, golfers that are expected to do better than others are given a higher salary.
As a part of my analysis, I need to figure out about how much a golfer is worth if they are projected to finish X best out of all the golfers. In other words: If a player is projected to finish 10th in the tournament, what should their salary be?
There are a few ways of thinking about this which I’ll explain below.
1) Use the actual salaries
I’m running this optimization and re-ranking of players on a week to week basis. So after I re-rank, I could just value the player in 10th place the 10th highest salary of the week. This is what I tried initially, but it gave some funky results. This week is the Memorial, and the 10th player (Tiger) has a salary of 10k, while the 11th players (Bill Haas) has a salary of 9.2k. That drop of 800 is huge when most of the mispricings are in the 400 range. In fact, by using this way of valuing players, Tiger was the worst priced player, and Haas was 2nd best priced player, all because of this gap. Clearly I’ll need a different method.
2) Since we’re actually trying to project how many points these players will score, use the average of points for players who finished in a certain position.
Quickest way to check on this is to graph the values and see what they look like. Sorry, Matplotlib isn’t exactly the prettiest to look at.
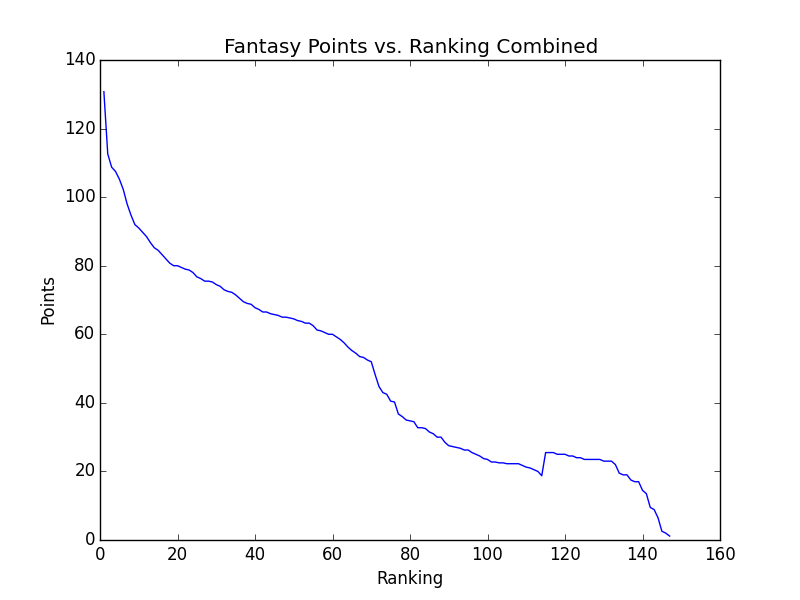
The graph above has that little hitch because I’m only using results from the Colonial and the Byron Nelson. With more results, we can hope to see something a little more standard. Also, I needed to do a little math on the results file that Draftkings gives after a contest is over. Take al look at that writeup here.
Another thing to note about the graph above is that noticeable dropoff around 70-75th place. Only 70 and ties make the cut for a PGA Tour event, and that drop indicates how important it is for players in your lineup to make the cut. If we can see the drop on this graph, you can tell how important it is for real.
3) Fit an exponential decay function to the average points scored to smooth out the plot
Theoretically, we should be seeing a very nice exponential decay for the point scored. The fit looks like the following.
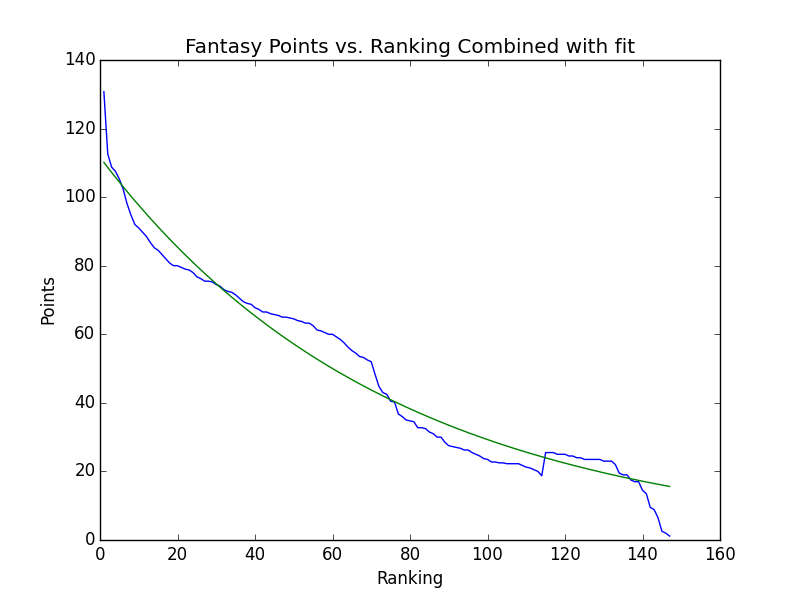
The fit looks pretty decent, but when running it against the past two week’s data, it seems like there isn’t enough variation from one spot to the next. This means that we aren’t able to differentiate as much as I’d like between the great plays and the ok plays.
4) Back to the salaries. They tend to drop off in decaying exponential fashion, so fit a function to the salaries, and use that.
The first step for this method was finding the average salary for each ranking from the salary files I have. Here’s a graph of what that looked like.
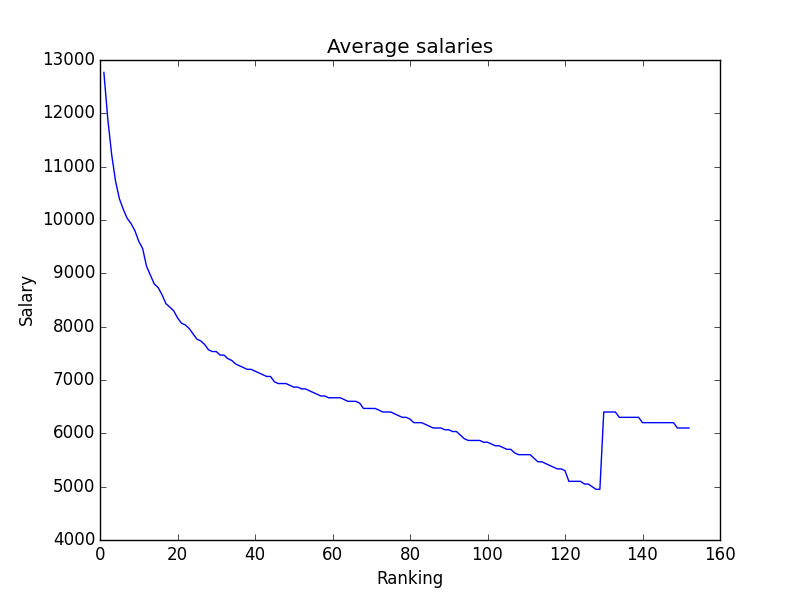
The hitch in the graph was from events that have a non standard field size, in this case, the Heritage and Colonial. To get rid of that hitch, I figured I’d only take into account the top 125 salaries.
I had two options for the fit, whether or not I would include a y0, or a bottom for the decay function. After graphing the two best fits, the answer to include a floor for the salaries was pretty clear.
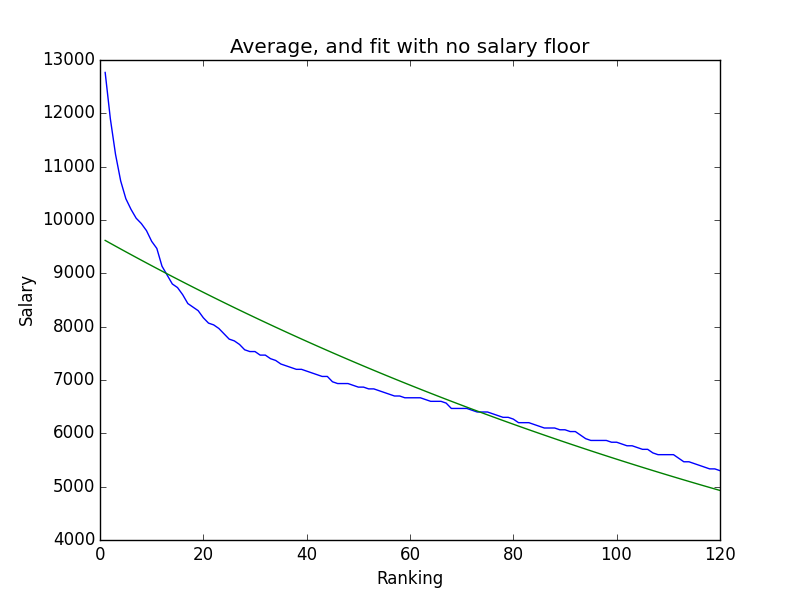
You can barely see the curve of the fit
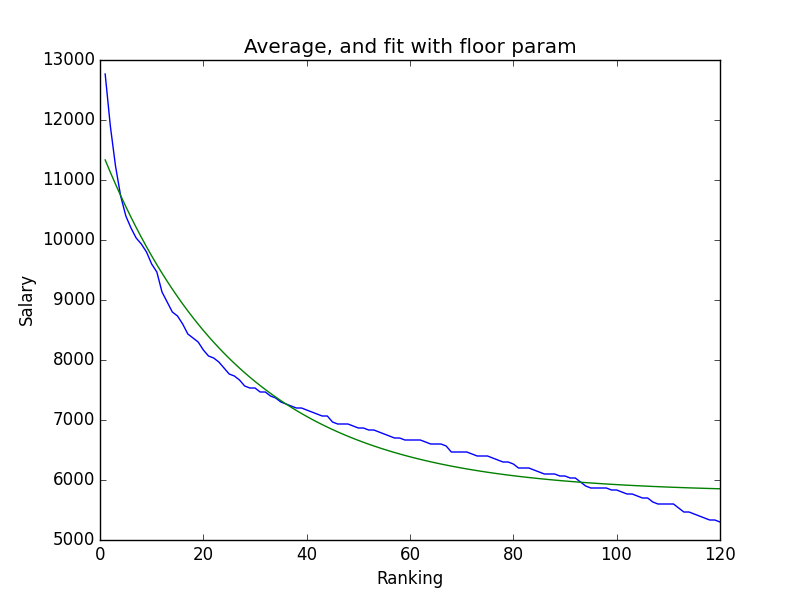
Much closer to the curve
But when I looked at this fit, I wasn’t really pleased with it. That addition ended up being about 6k (5792.21 rounded to two decimals), which meant that no player would ever have a salary lower than that. Since that isn’t the case at all, and sometimes playing golfers under that price point is a good idea, I needed to use the third and final way to figure out values.
5) Just use the averages of the salaries for all the rankings
In the end, all that work fitting a function was for nothing! This main advantage of just using the averages is that it uses actual salaries as a proxy so there’s no fitting. As we can see, the fit we used above didn’t really work too well because it doesn’t take into account the tailing off of the salaries. And when many of the value plays are around that salary level, we need to be as accurate as possible. And in the coming weeks when I have even better averages, these numbers should be better and better.
And by using this method, the initial results look good. In reality though, I need to build a testing method. One that picks a value function, optimizes lineups, and check to see which one actually gets the best results. I can do the eye test for now, but I’ll need hard numbers for real when I have a few more weeks of data. More to come.
Follow on twitter: @jack_schultz
