This post is guest-written by Alex Lacey, a student at The Ohio State University. It was inspired by the ideas (and used some of the code) from this previous Big-Ish data post.
Popular music is constantly evolving, and the changes it has undergone over the last few decades are quite significant. In this project, I have investigated the changes in sentiment (the positivity/negativity) of popular music lyrics since the 1950s. I wanted to know: has the sentiment of song lyrics evolved along with other musical changes?
For this sentiment analysis, I used four open-source lexicons: AFINN, NRC, Bing, and Syuzhet, all of which were developed by separate research teams. There lexicons, which each comprise of a large set of words and their corresponding human-rated sentiment scores (the positivity/negativity of each word) are all available in the R syuzhet package. Each method works in the same way: a full block of text (which, in this case, represents all of the lyrics of a given song) is separated into individual words based on spacing and punctuation. Each word is examined for its presence in the lexicon; if it is present, then that word is assigned its corresponding score in the lexicon, but if it is not present, the word is not assigned a score. After that, all of the available word-scores in a block of text are averaged to produce a sentiment score for the full block of text.
But what data is necessary to answer this question? What exactly defines the “popularity” of music? This is a subjective concept, so I used two separate (albeit somewhat overlapping) definitions as a proxy for popularity: best-selling songs and best-selling artists.
Best-Selling Songs
For data about the most popular songs, I used a dataset containing the 100 top-selling songs of each year from 1956 to 2015. That dataset was created by Kaylin Walker, a Statistics Masters Student at Concordia College, and it can be downloaded here.
I analyzed every song in the dataset – 5100 total – with all four Sentiment Analysis methods discussed above. However, comparing the scores of songs for each method was not initially possible: the methods have different scales and some methods might rate songs more positively or negatively than others in general. To solve this problem, the sentiment values for each method were converted to z-scores, meaning that the full set of song-scores were centered (so that the mean sentiment score equals 0) and then scaled (so that the standard deviation equals 1). This allows for the four lexicons to be compared against each other accurately. As an representative example, here are the results from the AFINN lexicon, with a simple regression line:
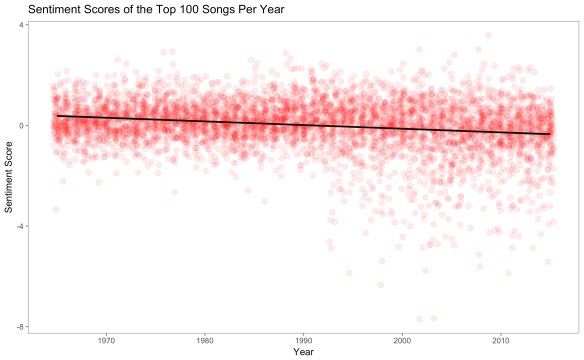
There is a statistically significant downward trend here, and interestingly, it seems to be caused not by the majority of songs, but by a minority of songs in recent decades that are highly negative. There is a great increase in the variance in the sentiment of popular songs, primarily in the downward direction. It is quite interesting that for many years, not one popular song was more than 4 standard deviations below the average, but starting in the 1990’s, this became relatively commonplace.
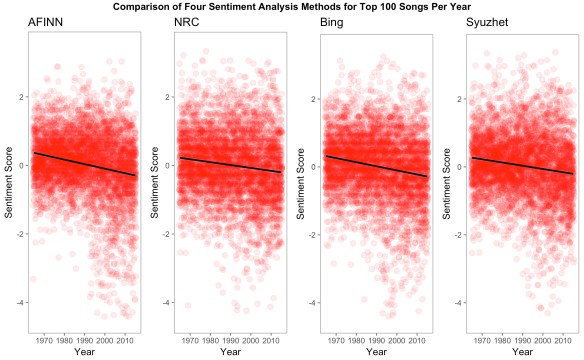
These same trends are reflected in all four sentiment lexicons (all of them are statistically significant):
But perhaps the highly-negative songs in recent years weren’t actually the most popular; of the top 100 for any given year, most people don’t hear the bottom 50 very often, and likely won’t be able to recognize them. I thought that maybe the songs with negative lyrics populate the lower rankings of the Top 100, perhaps greatly enjoyed by a counter-culture but not by most people (in general, genres like punk and metal often fall into this category). Whether or not a devoted cult-following constitutes “popularity” is up for debate, but it would be unfair to make final conclusions about changes in popular music based only on counter-cultures. To test only the hyper-recognizable and undeniably “popular” songs, I decided to do the same analysis on specifically the Top 10 most popular songs from each year, as opposed to the Top 100. The z-scores of the results from the AFINN lexicon are shown in the graph below. I included differential opacity-weighting for the songs as well (the most popular songs are a darker shade).
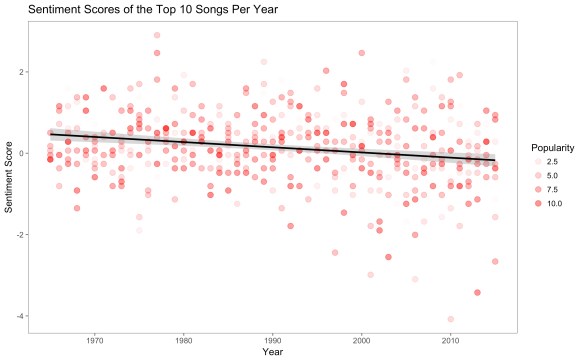
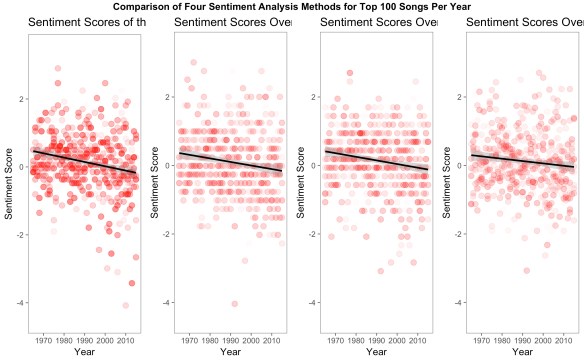
The initial observation holds true; there is still a significant drop in the negativity of the most-negative songs after 1990. This trend was found with all four sentiment analysis methods:
Most Popular Artists
Along with the most-popular songs, I also investigated lyrics from the most-popular artists, using their entire discography. This could augment the prior analysis by providing a clearer picture of everything written by the most influential lyricists, not just their songs on the radio. The list of 100 best-selling artists came from this list on Wikipedia. The specific years, which were assigned by the Wikipedia list, refer to the date in which each artist released their first charted single.To obtain the lyrics of each artist, I scraped Genius.com using Python code by Jack Schultz in this Big-Ish data post, in which he did a very interesting analysis of country music. Here are the AFINN lexicon results, the size of which represent the amount of sales, and the colors of which represent the genre of music:
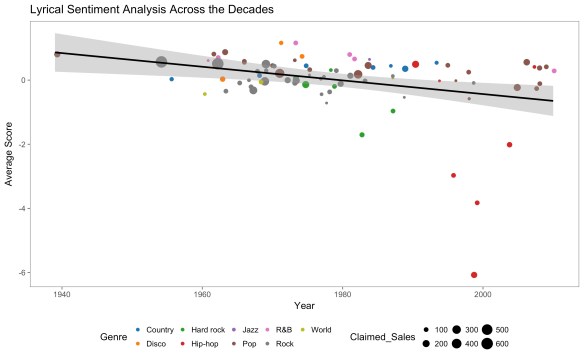
Roughly the same trend is observed as the analysis of the most popular songs (and in case you’re interested, the red dot that is six standard deviations below the average is Eminem). Just like before, here are the results for all four methods (note that to accurately portray most of the points, the graphs were all cropped, which resulted in the removal of a couple of artists above 1.75 standard deviations and a handful of artists below 1.75 standard deviations):
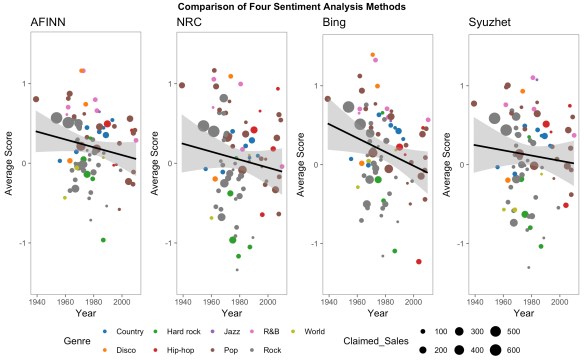
However, in consideration of these results, it is very important to note that increasingly-negative lyrics is not necessarily a bad thing. In fact, I believe the opposite: this is a demonstration of popular art becoming more interesting, more honest, more meaningful, and a better representation of the human condition. Music has continuously diversified and reinvented itself, and this is reflected in the lyrics too.
In the future, I plan to also investigate the sentiment of these lyrics with IBM’s Watson, specifically the AlchemyLanguage API. This would be particularly useful because it is a non-lexicon-based method (it considers how the words are arranged, not just the words themselves). This can be quite important. For example, lets briefly examine the phrase “I am not happy”, which we should all agree is an overall negative statement. The lexicon-based methods would likely give that phrase a positive sentiment score, because the first three words are relatively neutral, and the last word is quite positive. On the other hand, more advanced methods (such as IBM’s Watson), are able to understand that “not happy” is the opposite of happy, and they would likely classify the phrase correctly. However, even with the lexicon-based methods used in this analysis, I can assume with an acceptable degree of confidence that the results will be the same due to the relatively large amount of data.
