I’ve had a theory that for every Noodles, there’s a Qdoba that’s right next door. It might be some sort of selection bias however, since I can think of a couple locations where they’re directly next to each other. To me, Noodles and Qdoba have a special relationship, at least compared to other restaurants. I figured now was about the time I should test this, and I can use Chipotle to test.
The question is: Which restaurant is more special to Noodles, Qdoba or Chipotle?
Finding the Noodles, Qdoba, and Chipotle locations
Initially, I went to Noodle’s website and their locations page and was planning on getting the data from there. But what I realized was that it just used the Google Maps API to get it’s data, so I might as well just go right to the Google source and use their api correctly.
Google’s docs are pretty good in this case, and after grabbing an API key, I started in on finding the Dobas. For prototyping, I just started with the latitude and longitude of Milwaukee, my home town, and a place where I know there multiple Qdobas / Noodles pairs.
import requests
url = 'https://maps.googleapis.com/maps/api/place/nearbysearch/json'
location_milwaukee = '43.0389,-87.9065' #Milwaukee
params = {}
params['key'] = GOOGLE_PLACES_API
params['type'] = 'restaurant'
params['radius'] = 50000 #in meters, and going be an issue
params['keyword'] = 'Qdoba'
params['location'] = location
r = requests.get(url, params=params)
results = r.json()['results']
print results
Put your Google Places API key in the ‘key’ param, run those lines of code (assuming you pip installed requests) and you’ll see 20 Qdoba locations along with some extra information spit out on your console.
Issues
Two obstacles came up with this part of the project – one simple to fix, the other decently tough. First the simple one.
In order to limit the amount of information coming across the wire, Google limits each API request to 20 results. When there are more than 20 results they find, they also pass back in the json a param named “next_page_token”. So when we see this param passed back, we need to stick with the same location, and add the param “pagetoken” and hit the same endpoint. There’s also a time aspect to this request where we need to wait a couple seconds before hitting the endpoint to grab the remaining locations. Not too bad.
Second issue here, and somewhat of an annoying one, is the radius parameter. 50 km is not quite the size of the entire US. This is actually a really interesting problem that, after talking with work colleagues, there isn’t a straightforward solution. What we really need here, is a set of latitudes and longitudes where, with the 50 km radius, will cover the entirety of the United States. Sure you could put a location every miles or so, but that would take forever to search for. So instead of finding a solution to this problem isn’t in the scope of this article (maybe later). Instead, I found this nice gist of the top 246 metro locations in the US and their latitude and longitudes and am just going to use that and hope it covers enough of the country to be useful.
Complete code for this part of the project includes writing the locations of the restaurants to a tab separated values (tsv) file. Normally would use a csv, but since the addresses have commas in them, it could get confusing.
from major_city_list import major_cities
keyword_qdoba = 'Qdoba Mexican Eats'
keyword_noodles = 'Noodles & Company'
keyword_chipotle = 'Chipotle'
search_keywords = [keyword_qdoba, keyword_noodles, keyword_chipotle]
params = {}
params['key'] = GOOGLE_PLACES_API
params['type'] = 'restaurant'
params['radius'] = 50000
for keyword in search_keywords:
params['keyword'] = keyword
keyword_info = {}
for city in major_cities:
print city["city"]
location = "%s,%s" % (city["latitude"], city["longitude"])
params['location'] = location
while True:
r = requests.get(url, params=params)
results = r.json()['results']
num_results = len(results)
print "results: %s" % num_results
for result in results:
lat = result["geometry"]["location"]["lat"]
lng = result["geometry"]["location"]["lng"]
key = "%s%s" % (lat, lng * -1)
address = result["vicinity"]
info = {"lat": lat, "lng": lng, "address": address}
keyword_info[key] = info
try:
next_page_token = r.json()['next_page_token']
params["pagetoken"] = next_page_token
time.sleep(2)
except KeyError:
params.pop("pagetoken", None)
break
filename = "%s.tsv" % keyword
filename = filename.lower().replace(" ", "_")
with open(filename, 'wb') as tsvfile:
writer = csv.writer(tsvfile, delimiter='\t')
for key, info in keyword_info.iteritems():
writer.writerow([info['lat'],info['lng'],info['address']])
Final thing to point out here is about why I have this be a multi step process. I could have written a script that does this part, and then all the rest of the project at once. But you’ll find that when working on things and bugfixing, it’s better to split tasks up, save the results, and then use those results without having to go back out to the internet.
Finding nearest companion
Step two of this process here is finding the closest Qdoba and Chipotle for each Noodles. With that information, we can figure out how far away the nearest companion is. At first, I was tempted to go right back to the Google Places API since, well, it was designed for this purpose. However first, I decided to see if I could brute force it with the n^2 loop over every location and find the shortest distance algorithm. Turns out that was a great decision because it was way quicker and more accurate.
Code steps are 1) Read in the noodles.tsv file generated above, 2) read in the chipotle and qdoba .tsv files, 3) for each Noodles, loop the entire other file and store the closest location, 4) store that information in another tsv file. In this case, code is easier to figure out than explanation.
keywords = ['chipotle', 'qdoba']
noodles_locations = []
filename = "noodles.tsv"
with open(filename, 'rb') as tsvfile:
reader = csv.reader(tsvfile, delimiter='\t')
for row in reader:
noodles_locations.append(row)
for keyword in keywords:
information = []
filename = "%s.tsv" % keyword
keyword_locations = []
with open(filename, 'rb') as tsvfile:
reader = csv.reader(tsvfile, delimiter='\t')
for row in reader:
keyword_locations.append(row)
count = 0
for noodle_location in noodles_locations:
print count
test_loc = (noodle_location[0], noodle_location[1])
best_distance = 100000 #something large
for location in keyword_locations:
found_loc = (location[0], location[1])
distance = vincenty(test_loc, found_loc).miles
if distance < best_distance:
best_distance = distance
best_location = [location[0], location[1], location[2]]
info_row = [noodle_location[0], noodle_location[1], noodle_location[2], best_location[0], best_location[1], best_location[2]]
information.append(info_row)
count += 1
filename = "noodles_closest_%s.tsv" % keyword
with open(filename, 'wb') as tsvfile:
writer = csv.writer(tsvfile, delimiter='\t')
for info in information:
writer.writerow(info)
Analyze!
For my dumb theory to be true, there needs to be a disproportionate number of Qdobas and Noodles within walking distance of each other, and specifically, right next to each other compared to Chipotle.
After analyzing the data, I’m totally right.
I found 418 Noodles, 790 Chipotles, and 618 Qdobas. Even with the extra 172 Chipotles, there’s a Qdoba closer to a Noodles than there is a Chipotle.
Some numbers. If you’re at a Noodles, there’s a 12.7% chance you’re within 0.1 miles of a Qdoba, 19.9% chance you’re within 0.25 miles, and 35.9% chance you’re within 1 mile. Chipotle has percentages of 6.4%, 12.7%, 30.6% respectively.
Check out the histograms:
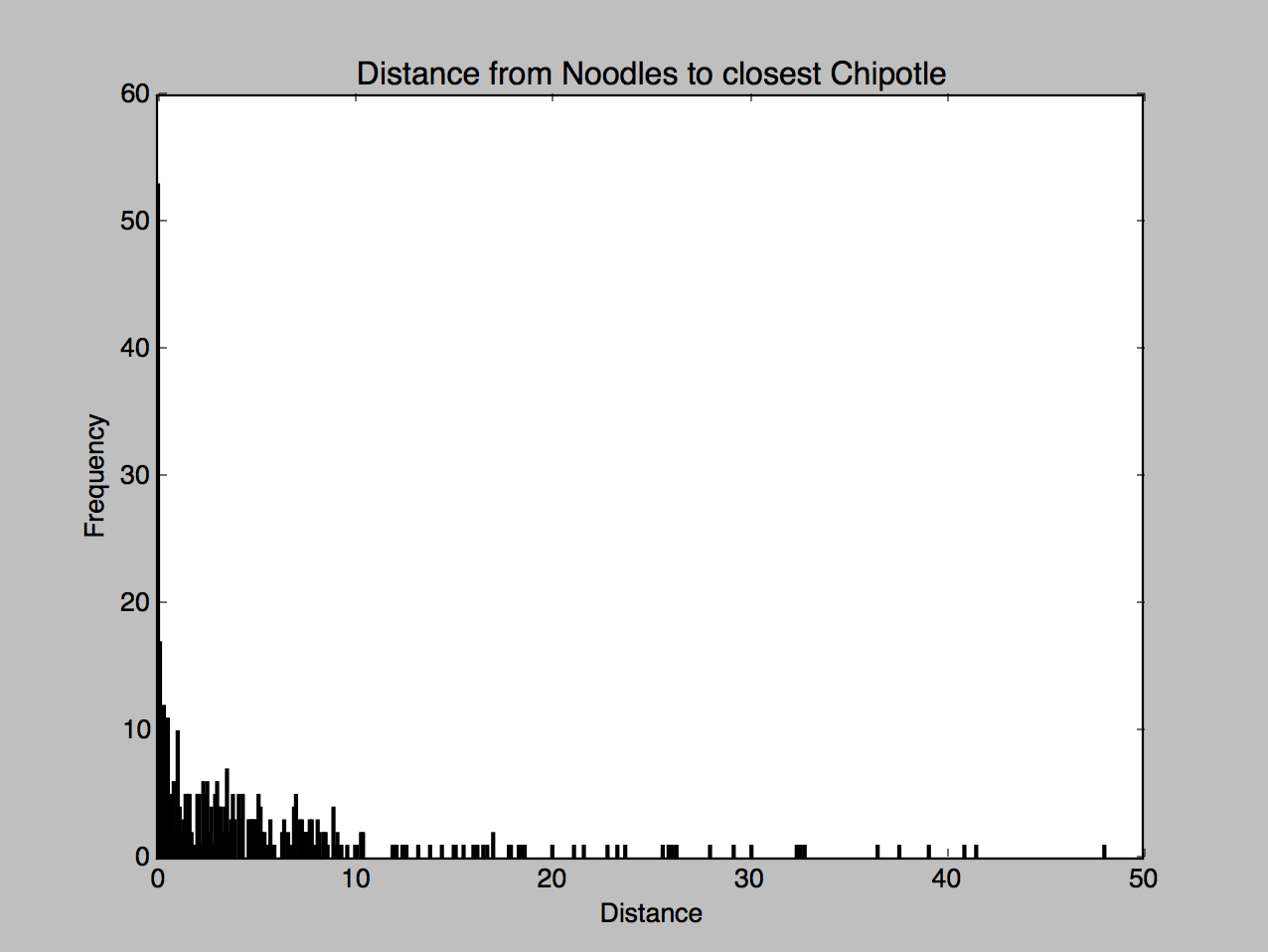
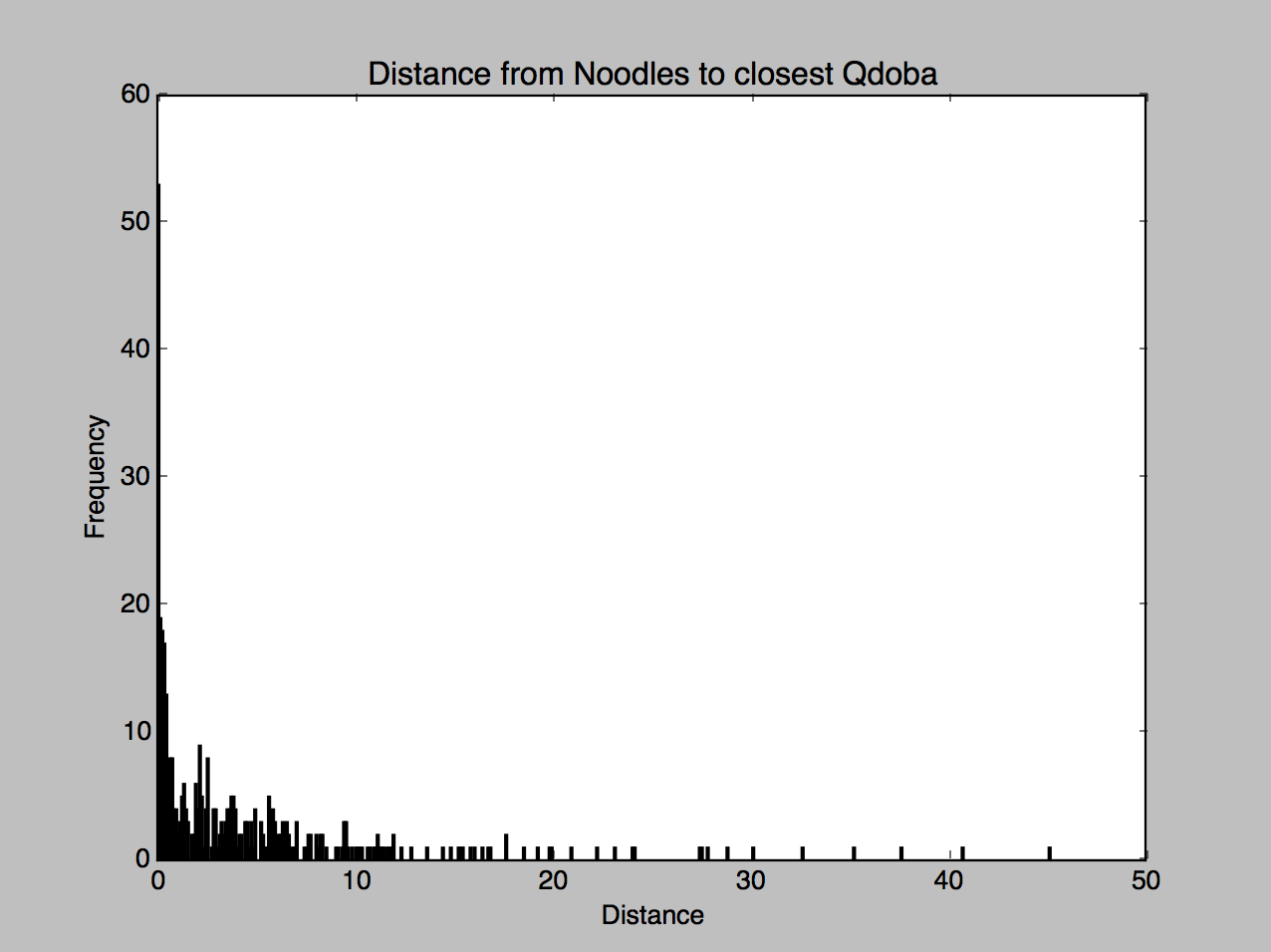
While not much of a difference, you can see a little more action on the left side of the Qdoba histogram compared to the Chipotle one.
As a final, final test, I went through each Noodle location again, found the nearest Qdoba and nearest Chipotle and counted the number of Noodles that had a Qdoba closer, and Noodles that had Chipotle closer. Final tally, 214 had a Qdoba closer, 204 had a Chipotle closer.
So how close are Qdobas and Chipotles from each other?
For fun, I ran the code to see how close the nearest Chipotle was from each Qdoba.
6.6% Qdobas had a Chipotle within 0.1 miles, 12.8% had one within 0.25 miles, and 28% within 1 mile. Semi-surprising that it was this high, but I guess people don’t want to go far for food.
The histogram is definitely more telling that Chipotles are further apart. Check out the y axis scaling here.
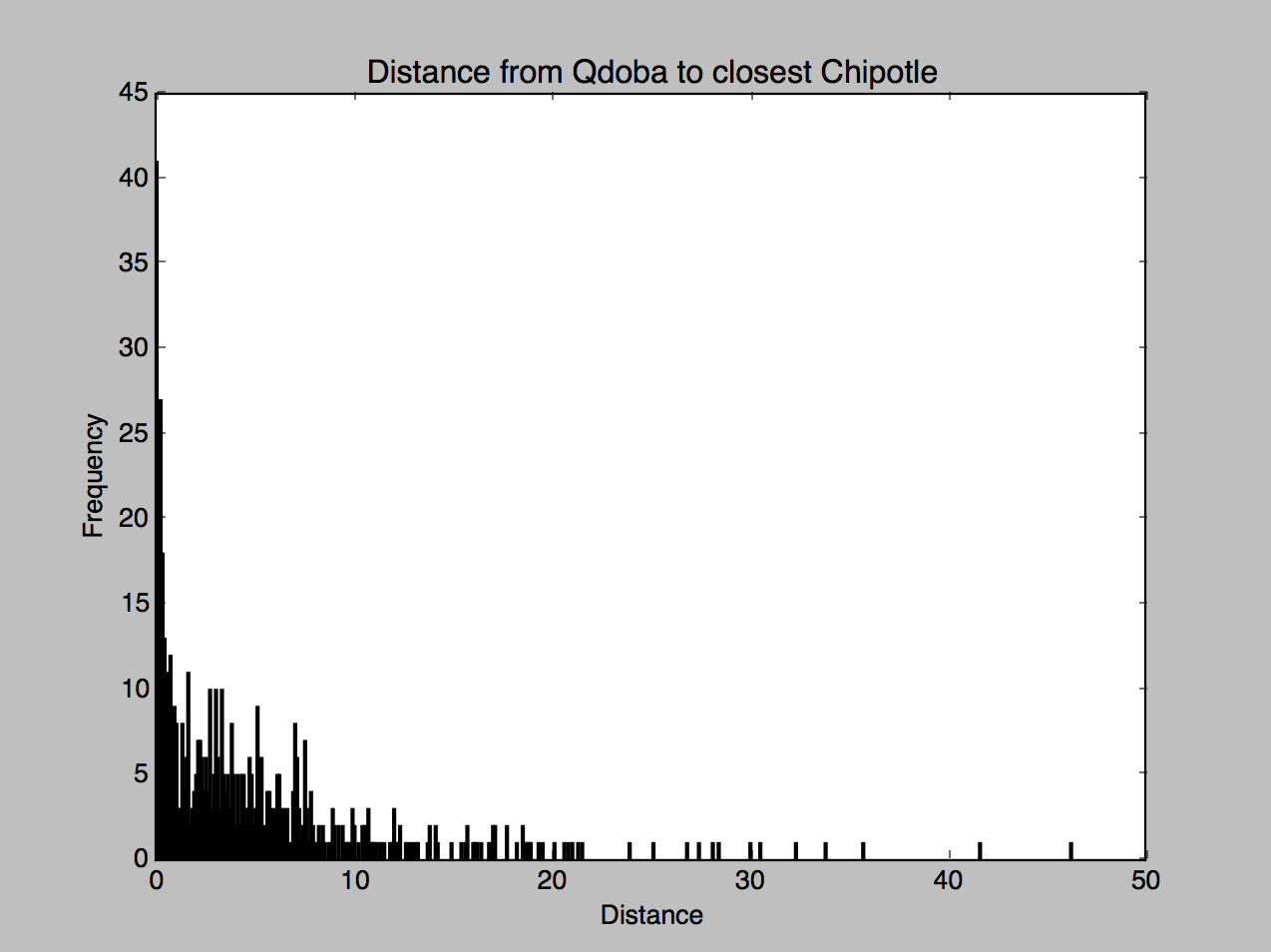
What’s the point of this?
Knowing this kind of information really isn’t all that useful. Fun, sure, but not too particularly useful. But what it does show is how powerful knowledge of the internet and programming can be. In just a short amount of time, we went from a dumb theory about restaurants to finding an answer. Also, maybe you’re looking to open a Qdoba somewhere in the US, and want to know if there’s a lonely Noodles that needs a companion!
Follow on twitter, and get in contact if you have information you want on the internet. I can help you out!

This is pretty cool. Could be useful for getting location data in another context some time in the future. Thanks!
LikeLike
Thanks, made me think tonight. I like your writing style. I need to adopt a more – ‘someone else might be reading this’ attitude with my blog. It makes it much more useful as a medium.
LikeLike